![[論文] SIGMOD/PODS 2024 クラウドデータウェアハウスの性能を向上させる新技術「Predicate Caching」](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1729349232/user-gen-eyecatch/clrr5411194hegmgsmxm.jpg)
[論文] SIGMOD/PODS 2024 クラウドデータウェアハウスの性能を向上させる新技術「Predicate Caching」
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。SIGMOD/PODS 2024にて、「Predicate Caching」と呼ばれる新しいインデックス技術を発表されました。この技術は、繰り返し実行されるクエリパターンを活用して、クエリ処理を高速化します。この技術を論文をベースに解説します。
なお、仕組みを知りたい方は、「4 PREDICATE CACHE」から読むのがおすすめです。
Predicate caching: Query-driven secondary indexing for cloud data warehouses
クラウドデータウェアハウスでは、同じクエリを頻繁に送信される傾向があります。従来のクエリのパフォーマンスを向上させる方式は、更新によってキャッシュが古くなる課題がありました。この問題に対処するため、論文では繰り返されるスキャンと結合のクエリレイテンシを改善するための新しい二次インデックス「Predicate Caching」を提案しています。
ABSTRACT
クラウドデータウェアハウスでは、同じクエリが頻繁に実行されることが多く、Amazon Redshiftなどのシステムは、結果キャッシュやマテリアライズドビューを用いてパフォーマンスを向上させているが、データの更新によりキャッシュが古くなることがある。
そこで、繰り返されるスキャンやジョインのクエリ応答時間を改善するために、「Predicate Caching」という新しい二次インデックスを提案する。これは軽量で、再計算なしでオンラインで維持できます。このプロトタイプを Amazon Redshift に実装したところ、ビルドのオーバーヘッドがほとんどない状態で、選択されたクエリのクエリ実行時間が最大10倍向上することが示されています。
1 INTRODUCTION
クラウドデータウェアハウスは過去10年間でデータ分析市場を席巻しました。Amazon RedshiftやSnowflakeのようなシステムは、高速で拡張性が高く、柔軟性があり、ほぼ無制限のストレージ容量を提供しています。これらの成功は、高度に分散化された並列クエリエンジンに基づいており、日々何百万ものクエリを処理しています。
本論文では、分析クエリを高速化するための実用的な技術である**「Predicate Caching」**を紹介します。この技術は、頻繁に使用されるベーステーブルのスキャン式を、該当する行範囲とともにキャッシュするというものです。クラウド分析のワークロードとクエリが高度に反復的であることから着想を得ており、Amazon Redshiftクラスターの50%以上で、少なくとも75%のクエリが1ヶ月以内に繰り返されることが分析で示されています。
反復的なワークロードを活用するための標準的な技術はキャッシングですが、Predicate Cachingはクエリ処理の副産物として実装でき、維持コストが低いという利点があります。結果キャッシングと比較すると、Predicate Cachingはより柔軟で広範囲に適用可能な解決策となる可能性があります。
この技術は、下記の基準で評価されます。
- 構築オーバーヘッド
- キャッシュの作成に必要な時間
- 保守オーバーヘッド
- ワークロードまたは基礎データが変更された場合にキャッシュを更新するために必要な時間
- ゲイン
- パフォーマンスの向上の可能性
- ヒット率
- キャッシュによって応答されるクエリの比率
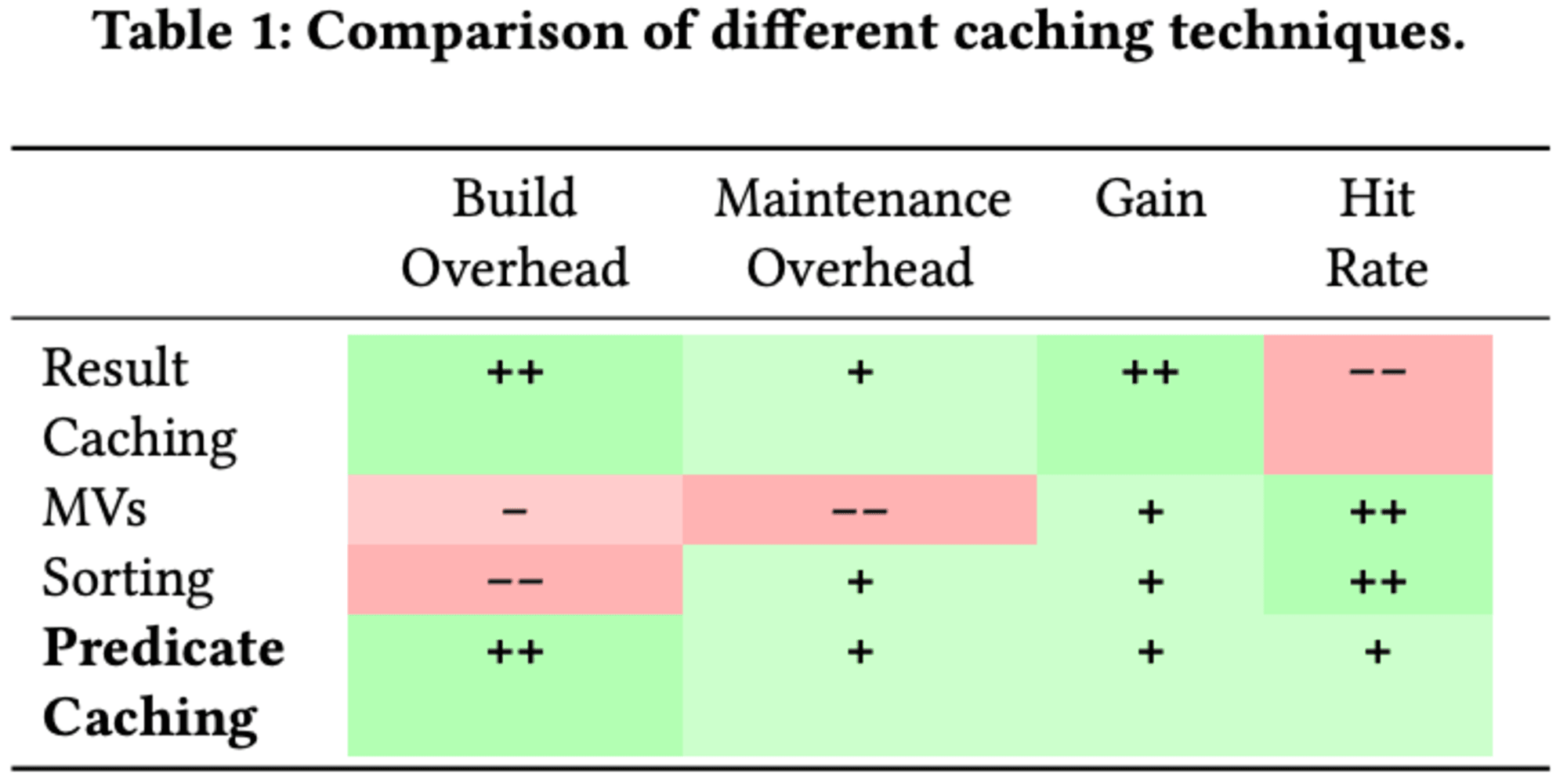
マテリアライズドビュー(MV、以降MVと略す。)は構築と維持に高コストがかかり、結果キャッシングと比べて速度向上が低いことが多いです。これは、MVがメモリではなくディスクやクラウドストレージに保存されることが多いためです。しかし、クエリ構造の一般化により、類似したクエリに対する適用率は高くなります。
データのソートやクラスタリングも反復クエリの高速化に有効ですが、データや負荷分布の変化に対応するのが困難です。一方、Predicate Cachingは結果キャッシングとMV/ソートの中間に位置し、低い構築・維持コストと高いヒット率を両立します。新しい負荷やデータ分布にも迅速に適応できます。
クラウドデータウェアハウスでは通常インデックスを維持しませんが、クエリの反復性を考えると、この前提を再考する時期に来ています。クエリ駆動型の二次インデックスは、クエリに最も関連するデータのみをインデックス化します。Predicate Cachingは、一回でインデックスを構築し、スキャン式から行範囲へのマッピングを逆インデックスとして保存します。
Predicate Cachingは選択性の低いクエリにも対応し、結合も考慮します。キャッシュエントリは、ベーステーブルの述語だけでなく、結合の述語も含むことができます。これにより、結合の効果を捉えることができます。
実験では、選択されたクエリで最大10倍の実行時間改善が示され、性能低下を厳密に回避しています。Predicate Cachingの構築と維持のオーバーヘッドはほとんど測定できないレベルで、メモリ消費はエントリあたり数メガバイト以内です。顧客の負荷では、最大90%のヒット率が観測されています。
2 WORKLOAD ANALYSIS
2023年1月にRedshift クラスターの代表的なサンプルからワークロード パターンを分析します。さまざまなキャッシュ手法がどの程度効果的であるかに焦点を当てています。
2.1 Query Repetitiveness
キャッシュは、システムの作業負荷が時間とともに繰り返されるという前提で機能し、結果の再利用が可能です。クエリの反復性が高いほど、キャッシュの効果が増大します。
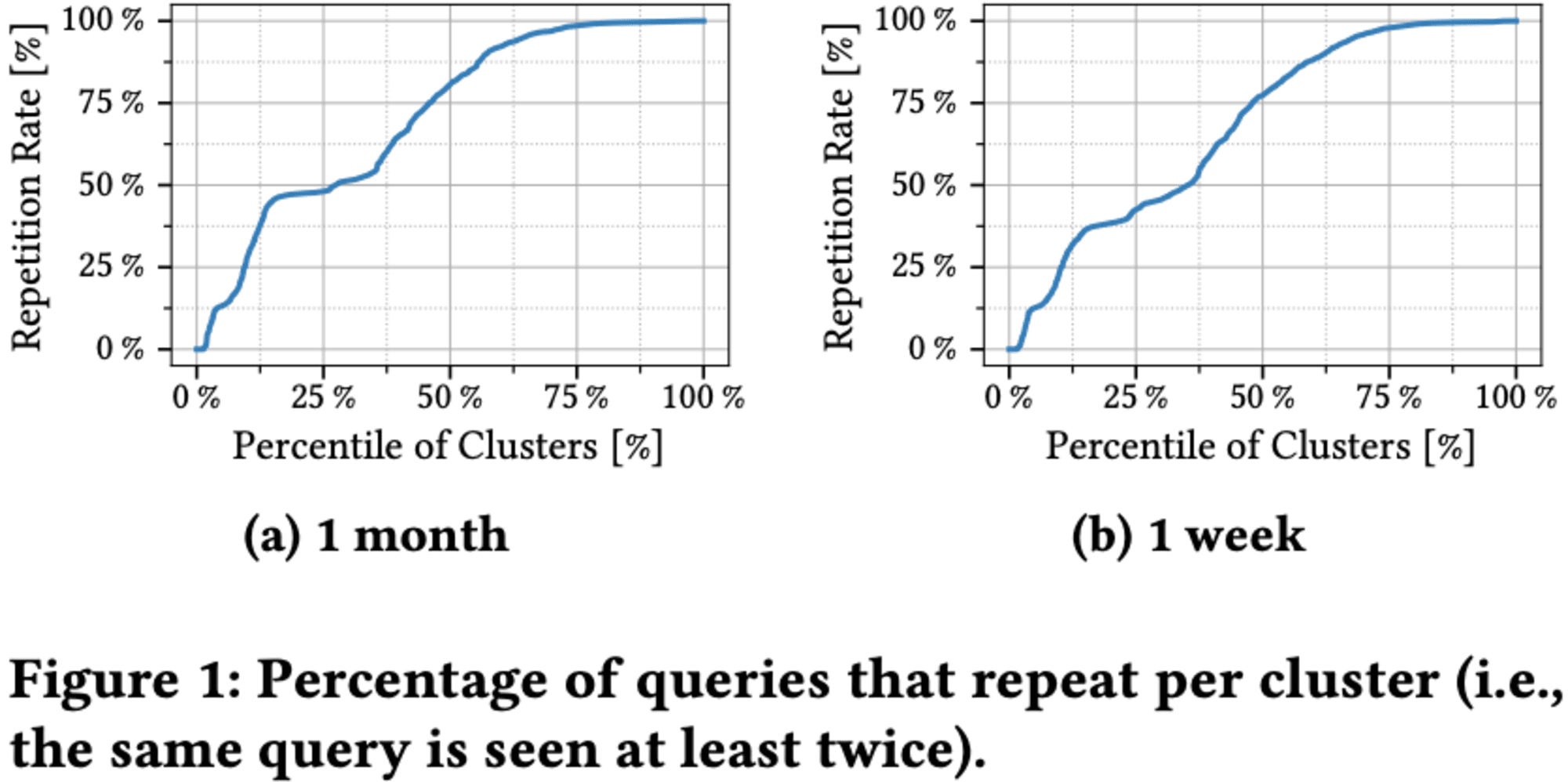
多くのクラスターで高い割合のクエリが繰り返されています。クラスターの50%は75%の繰り返されるクエリで、特に最後の25%のクラスターではほぼ100%のクエリが繰り返されています。これは、定期的なデータ分析やレポート作成のためのクエリが頻繁に実行されるという、BI用途の特性を反映しています。
2.2 Executed Statements
クエリの繰り返し率だけでなく、実行されるSQL文の種類も考慮する必要があります。多くのキャッシュ技術は、基礎となるデータセットが変更されない限り効果的です。そのため、クラスターで一般的に実行されるSQL文の種類とそれらがキャッシュの有効性に与える影響を分析することが重要だと指摘しています。
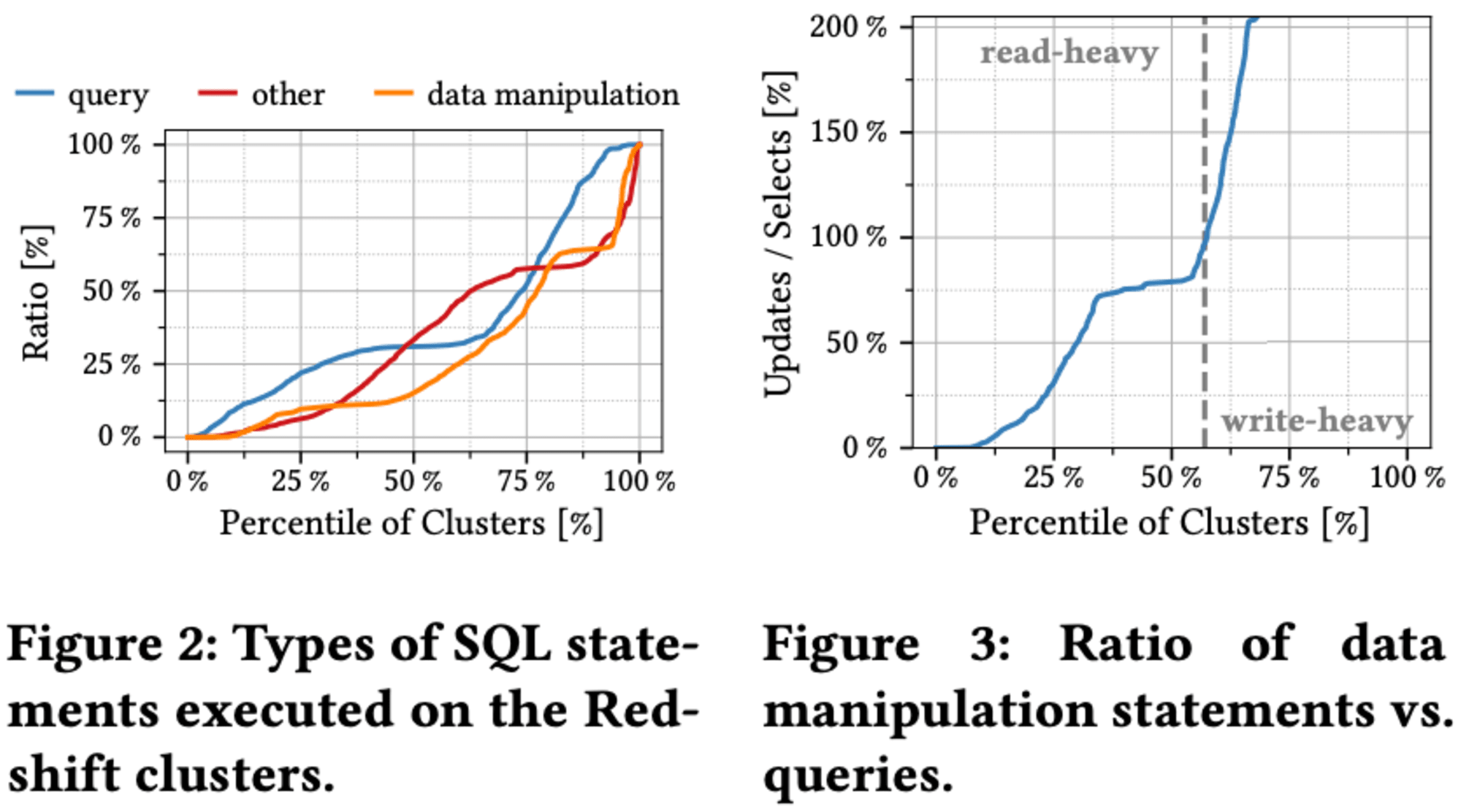
Redshiftクラスターでの異なるタイプのステートメントとそのクエリミックスへの寄与について分析が行われました。ステートメントは、select文、データ操作文(insert、update、delete、copy)、その他の3カテゴリーに分類されます。予想に反して、**select文が主体(50%以上)のクラスターは全体の25%**にとどまり、データ操作文も同程度の割合を占めています。実際、60%のクラスターで読み取りクエリが書き込みクエリより多く、残りの40%では逆の傾向が見られ、実世界での多様なクエリミックスが明らかになりました。
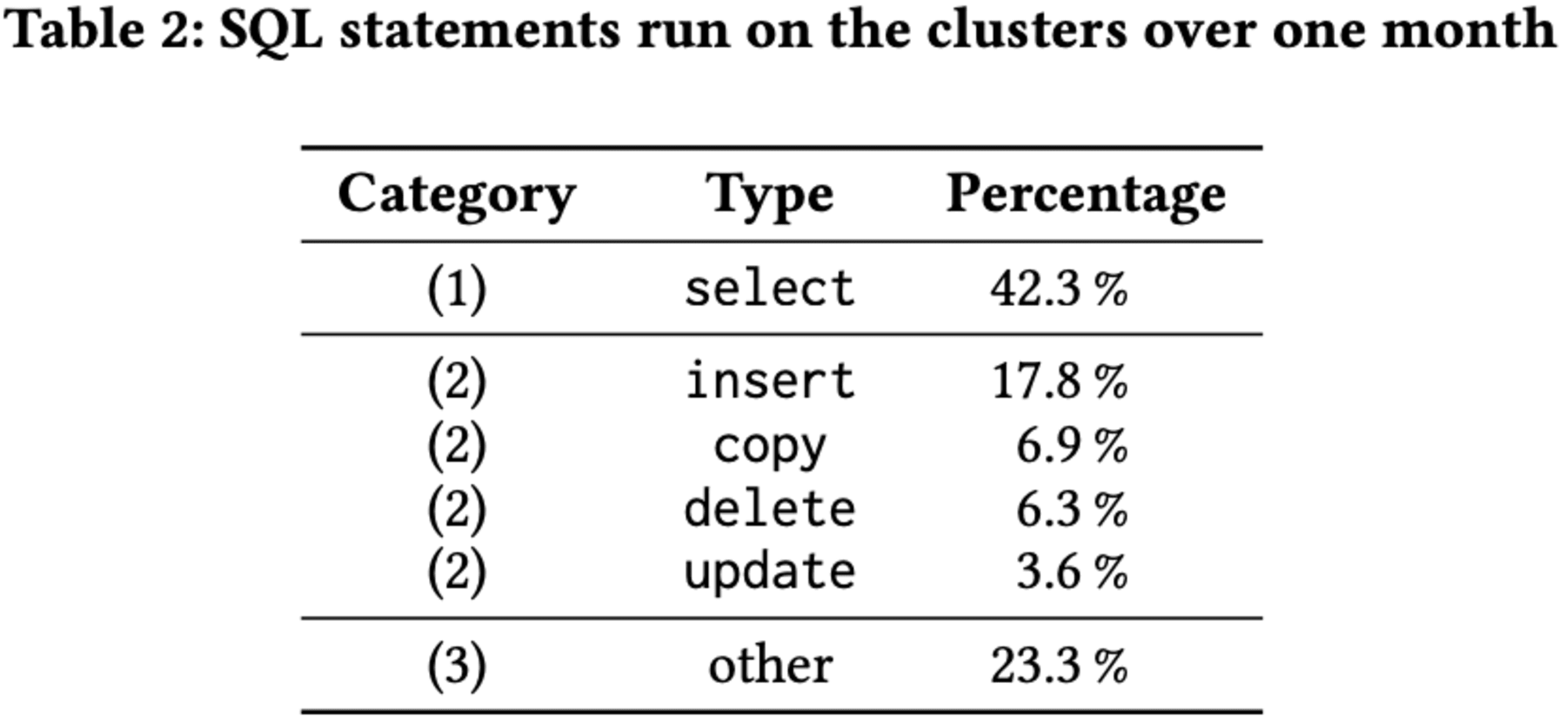
select文以外では、insertとcopy文がワークロードの24.7%を占め、最大の割合となっています。一方、deleteとupdate文は9.9%と比較的少ない割合です。残りの23.3%は、テーブルの作成や変更、分析、バキューム処理などの操作が含まれており、これらは顧客または自動的にシステムによって実行されます。
2.3 Scan Repetitiveness
クエリの高い反復性と定期的に変化するデータという特性が、キャッシュ実装に課題を提起しています。この分析結果を踏まえ、クエリの一部のみをキャッシュする方法の有効性を探ります。
述語キャッシュは、テーブルスキャンの必要なタプルの範囲のみを保存し、クエリ結果をキャッシュせずに不要なタプルへのアクセスを回避します。この手法の有効性を、フィルタ条件付きスキャンの反復性の分析を通じて検討します。
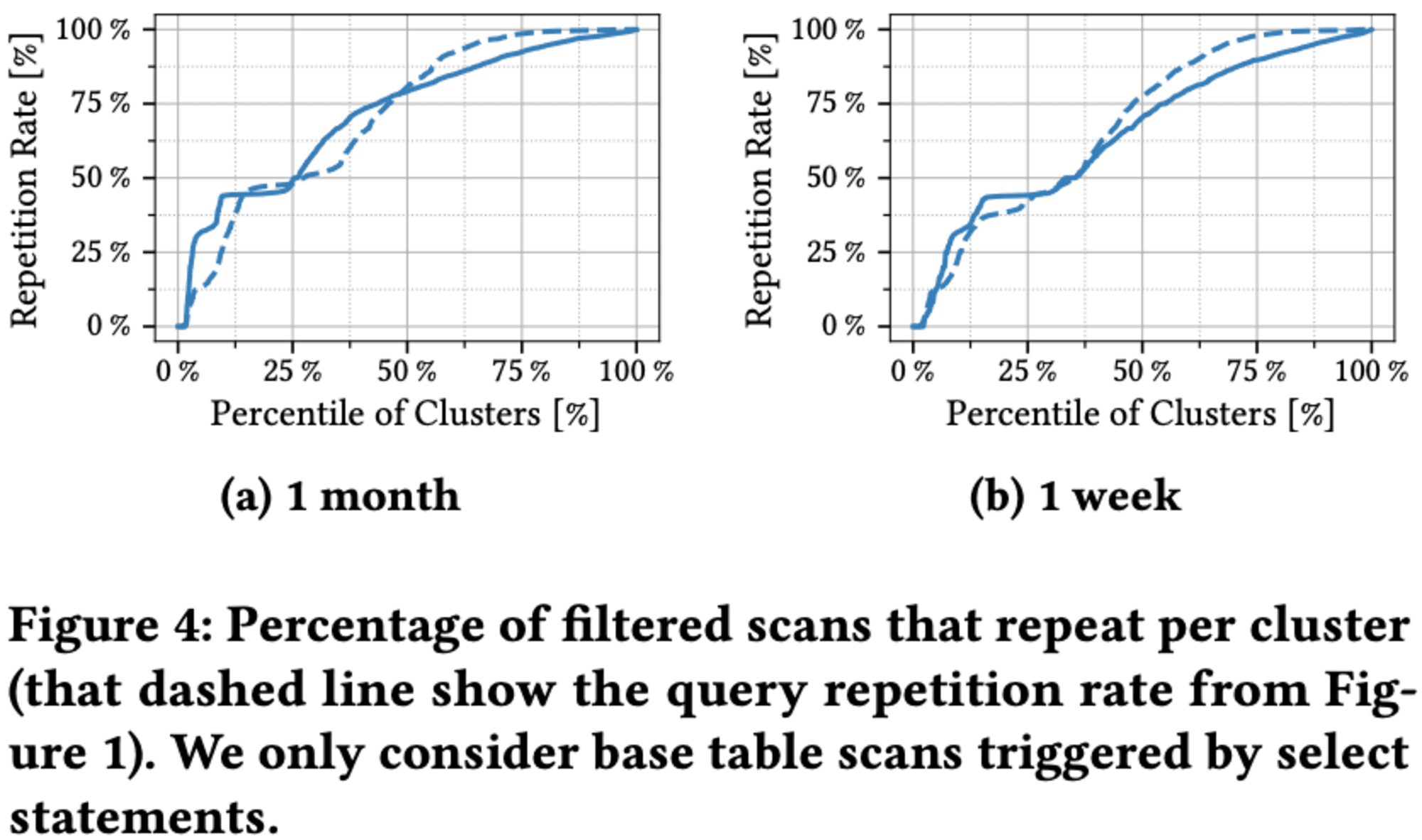
両者の率はほぼ同一ですが、わずかな違いが見られます。クエリが複数のスキャンで構成される場合があり、各スキャンを個別にカウントするためです。その結果、異なるクエリが同じスキャンを共有する可能性があり、スキャンの繰り返し率が高くなります。また、フィルター条件付きのスキャンのみを考慮します。一部のクラスターは主にフルテーブルスキャンを実行するため、繰り返し率は低くなります。
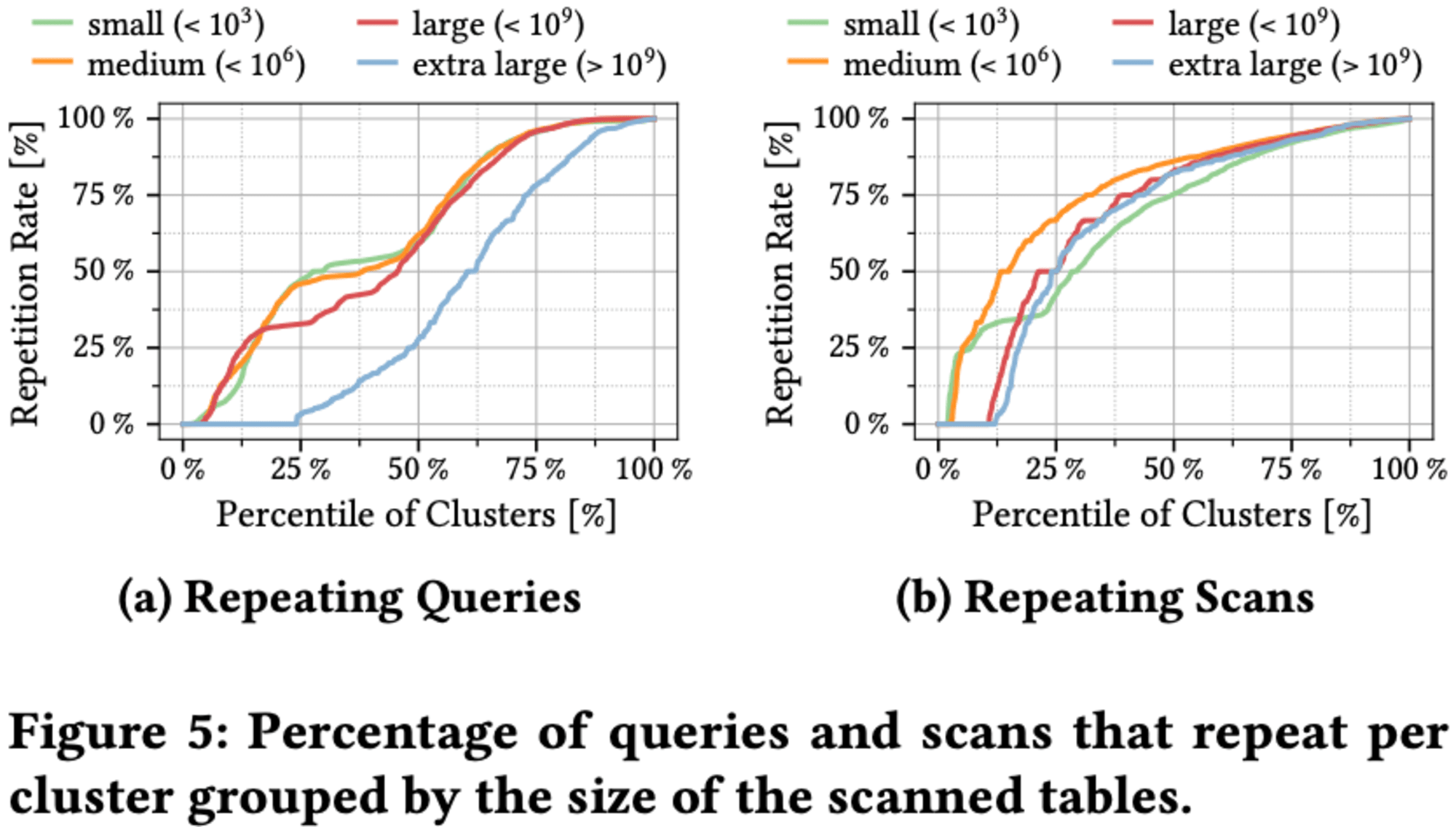
スキャンとクエリはそれぞれ71.9%と71.2%の高い繰り返し率を示します。テーブルサイズによる分析では、大規模テーブルに対するクエリは小規模テーブルよりも繰り返し率が低い傾向がありますが、スキャンではこの傾向が見られません。スキャンの繰り返し率はテーブルサイズにかかわらずほぼ一定で、特に大規模テーブルでも高い反復率を維持するため、クエリのキャッシュに代わるスキャンのキャッシュが効果的な選択肢となる可能性があります。
2.4 Takeaways
分析から、次の結論を導き出すことができます。
- クラウドデータウェアハウスのワークロードは非常に反復的であり、顧客は同様のクエリを繰り返し送信する
- データセットが定期的に更新されるため、クエリ結果全体を保存するキャッシュを実装することが困難
- SELECT 文はワークロードの42.2%しか占めず、分析システムで予想されるよりも少ないです
- スキャンはクエリと同様に反復的であり、代わりにキャッシュする価値がある可能性があります。特に、大きなテーブルのスキャンはクエリとして繰り返される可能性が高い
3 DESIGN OBJECTIVES
クラウドデータウェアハウスにおける繰り返しワークロードを活用する3つのキャッシング技術である、結果キャッシング、クエリテンプレートに基づくマテリアライズドビューの計算、ワークロードに適応したデータレイアウトの3つの手法が紹介されています。これらの分析から、キャッシュのオーバーヘッドを最小化し、ヒット率を最大化するための4つの設計目標が導き出されています。
3.1 Result Caching
クラウドデータウェアハウスにおける結果キャッシングは、最近実行されたクエリの結果をクラスターリーダーノードのローカルキャッシュに保存する簡単な技術です。同じクエリが再度送信された場合、データベースはキャッシュから即座に結果を返します。
この方法は、データベースやクエリ実行エンジンの変更を必要としない軽量な技術であり、構築や維持のオーバーヘッドも低く、キャッシュヒット時の性能向上も顕著です。しかし、主な欠点はヒット率の低さにあり、多くのクラスターでキャッシュからの応答率が50%を超えることは稀です。
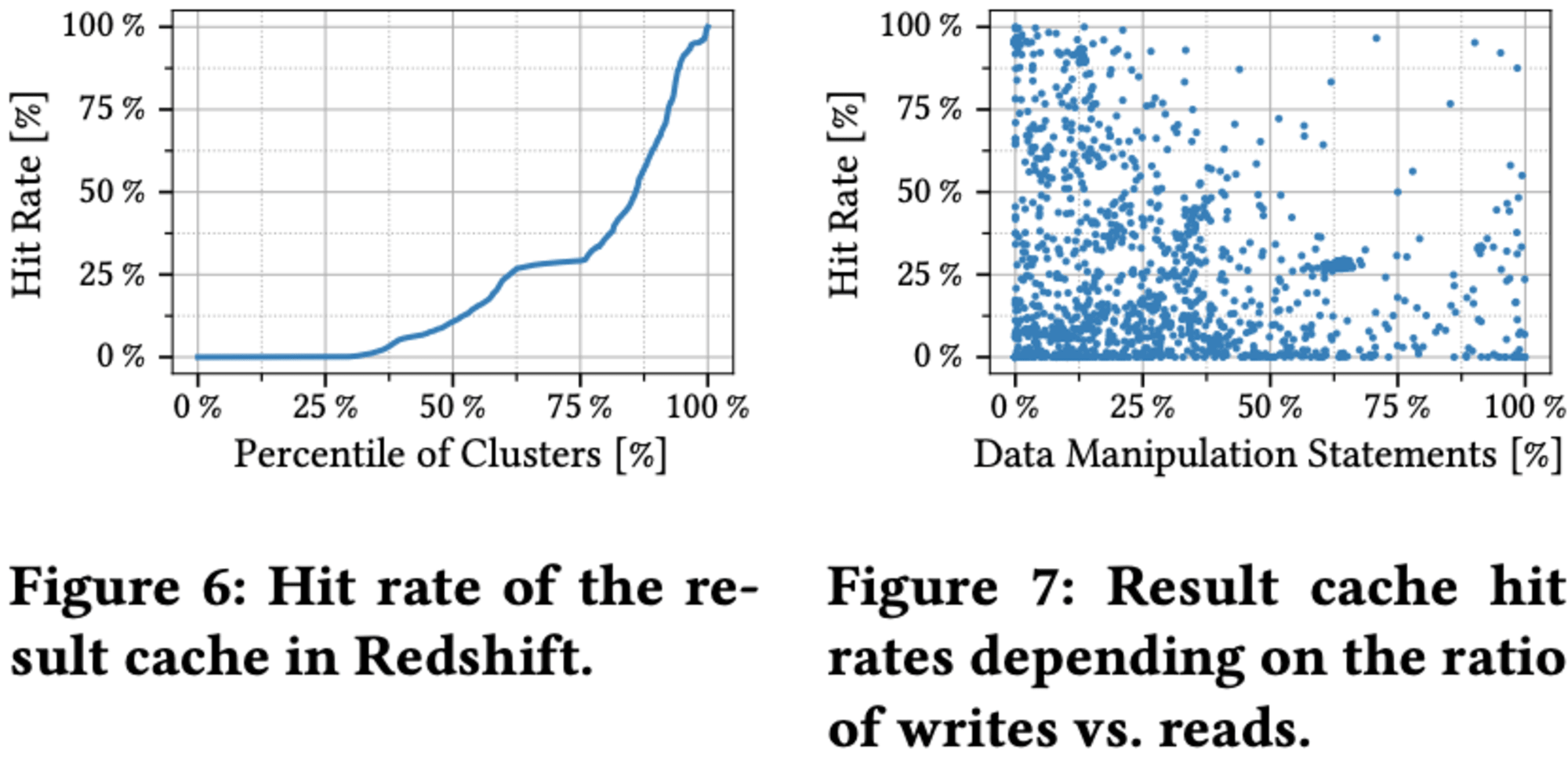
Redshiftは長時間実行のクエリに特化した分析システムですが、更新操作も重要な部分を占めています。特に、新しいデータを挿入するクエリは全体の約4分の1を占めています。データベースを変更するクエリは結果キャッシュのヒット率に大きな影響を与え、更新が少ないクラスターでは80%以上のクエリがキャッシュから回答されますが、更新率が上がるとヒット率は大幅に低下します。
しかし、結果キャッシュは軽量な設計と低いオーバーヘッドのため有効な選択肢です。RedshiftだけでなくSnowflakeやDatabricks、Google BigQueryなど他のクラウドデータウェアハウスも結果キャッシュを実装しています。
3.2 Materialized Views
Redshiftは、繰り返しのワークロードを活用するために、結果キャッシングに加えて**自動マテリアライズドビュー(AutoMV)**を実装しています。この技術は、類似のクエリテンプレートを識別し、それらをキャッシュするためのマテリアライズドビューを作成します。AutoMVは、既存のデータベースシステム上に構築され、ビューの作成、保存、更新、およびクエリの書き換えに既存のメカニズムを利用します。
AutoMVは、結果キャッシュよりも柔軟で広範囲のクエリに適用可能ですが、維持コストが高くなります。クラスタのストレージに保存され、基となるデータの変更時に更新が必要となるため、オーバーヘッドが大きくなります。しかし、クエリサブプランの抽出と一般化により、ヒット率が向上します。
Redshiftは、述語の昇格などの技術を使用してマテリアライズドビューを一般化し、より多くのクエリにマッチするようにしています。これにより、AutoMVは結果キャッシングよりも広範囲のクエリに対応できますが、期待されるコストは低く、維持コストが高くなるトレードオフがあります。

3.3 Sorting
結果キャッシングとAutoMVはクエリレベルで動作し、SQL文の結果をキャッシュします。これらの手法の主な欠点は、基礎となるデータが変更されるとキャッシュされた結果が無効になることです。
一方、Qd-treeフレームワークは、ワークロードに応じてテーブルを分割し、クエリのフィルタ述語に基づいてデータレイアウトを最適化します。これにより、同様のクエリパターンを持つ後続のスキャンで、テーブルの特定の部分をスキップできます。Qd-treeは完全一致を必要とせず、類似のパターンを持つクエリも活用できるため、AutoMVと同様のヒット率の利点を提供します。
しかし、大規模なテーブルの再構築には数時間かかるため、構築オーバーヘッドが主なボトルネックとなります。また、ワークロードの変化に対する適応性は低く、クエリのフィルタ述語が時間とともに変化する場合、テーブルレイアウトの再構築が必要になります。
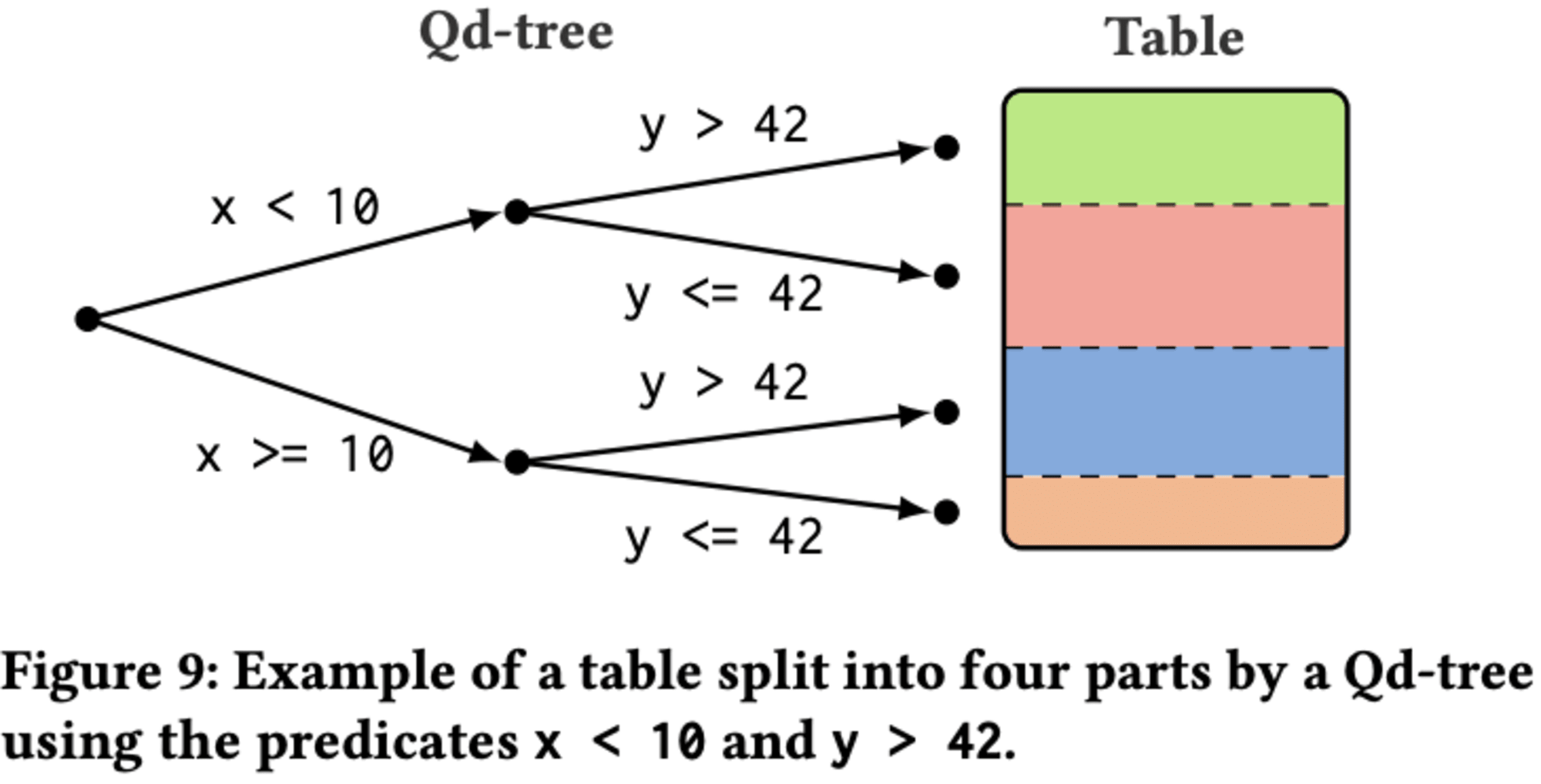
3.4 Objectives
既存の技術の欠点を補完するため、オンライン性、軽量性、オンザフライ構築、データ独立性という4つの主要な設計目標が設定されました。Predicate Cachingは、これらの目標をすべて満たすように設計され、リアルタイムでデータを最新に保ちつつ、リソース使用を最小限に抑え、クエリ実行の副産物としてキャッシュを構築し、基礎データの変更に影響されないキャッシュエントリを維持します。
この新技術は、結果キャッシュや物理ビューなどの既存技術を補完し、実世界のワークロードの反復的な性質をさらに活用することを目指しています。また、クラウドデータウェアハウスやデータレイクなど、さまざまなデータ管理システムと統合可能です。
4 PREDICATE CACHE
Predicate Cachingは、データを再編成せずにテーブルを維持しながら、スキャンの条件を満たす行の範囲を記憶する手法です。これにより、同じスキャンが再実行される際に、キャッシュされたエントリを使用して不適格な行をスキップし、クエリのパフォーマンスを向上させることができます.
4.1 Design
1995年1月の注文で多数の割引商品を含むものを検索するクエリを例に挙げています。
select count(*) from lineitem, orders
where l_discount = 0.1 and l_quantity >= 40
and o_orderkey = l_orderkey
and o_orderdate between '1995-01-01' and '1995-01-31'
このシステムは、述語キャッシュを使用して、lineitemテーブルとordersテーブルに対する条件をキャッシュします。同じクエリが再度実行された際に、条件を満たさないデータをスキップし、テーブルの一部のみにアクセスすることで効率化を図ります。述語キャッシュには2つの実装があり、固定サイズのメモリを使用するものと、テーブルサイズに応じて拡張するものがあります。
4.1.1 Range Index
Range Indexは、述語キャッシュにハッシュテーブルを用いて行範囲のリストを格納します。しかし、この方法は空間効率が悪いため、隣接する範囲をマージして一定数の範囲に制限します。これによりスペースの消費を抑えられますが、精度が低下し偽陽性が発生するため、キャッシュされた行に対して述語を再評価する必要があります。マージされた範囲はデータのスキャン中にオンザフライで計算され、レコードが該当しない最大のギャップをヒープで管理します。スキャン後、ギャップは範囲に変換され、述語キャッシュに挿入されます。
4.1.2 Bitmap Index
Bitmap Indexは、ハッシュテーブルを使用してキーをビットマップにマッピングする実装方法です。各ビットはタプルのブロックを表し、セットされている場合はそのブロックが述語を満たすことを示します。**ビットマップの構築は範囲のリストの計算と結合よりも高速ですが、精度が低く、エントリの選択性も低くなります。**この方法は、ブロック全体をスキップする最小最大境界や小規模な具体化集約に類似しています.
上記2つの実装は類似しており、同程度の高速化を達成しますが、必要なスペースと精度に若干の違いがあります。現在の実装では、クエリオプティマイザによってプッシュされたすべての述語をキャッシュしていますが、コストベースの最適化やSMTソルバーを使用した正規化により、さらなる改善の余地があることが示唆されています。
4.2 Integration into Amazon Redshift
Redshiftは、AWSクラウド環境向けに設計された拡張性の高いデータウェアハウスです。列指向ストレージエンジン、最適化された圧縮形式、分散マルチスレッドクエリエンジン、C++ベースのクエリコンパイルフレームワークを実装して、分析パフォーマンスを向上させています.
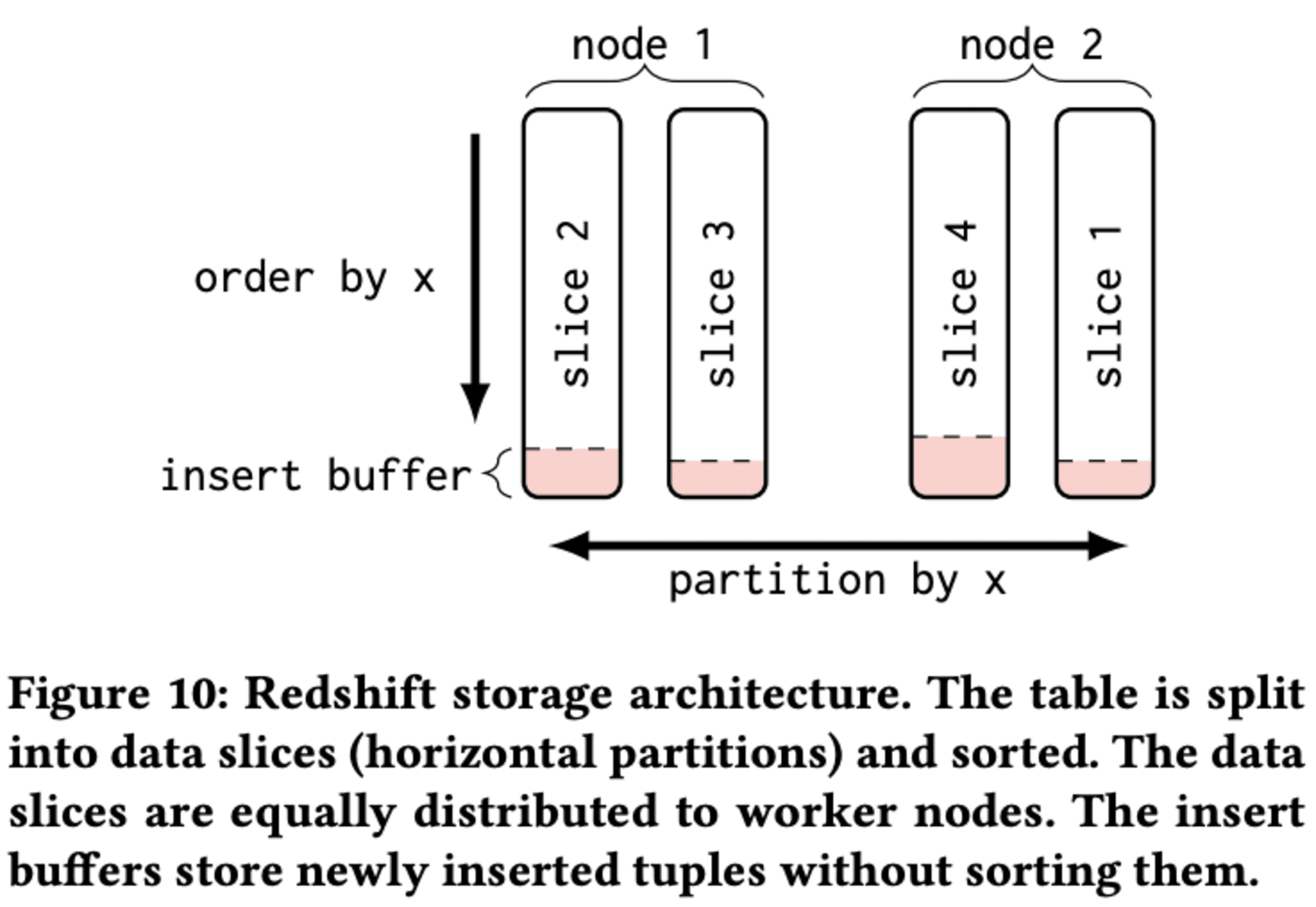
4.2.1 Storage Architecture
Redshiftのストレージアーキテクチャは、分散クエリ処理を効率的にサポートするために設計されています。データはディストリビューションキーに基づいてスライスに分割され、各スライスはグローバルソートキーで順序付けられます。これらのデータスライスは、Redshift Managed Storage (RMS)に物理的に保存され、コンピュートノードがS3から必要に応じてダウンロードします。
**4.2.2 Scan Processing **
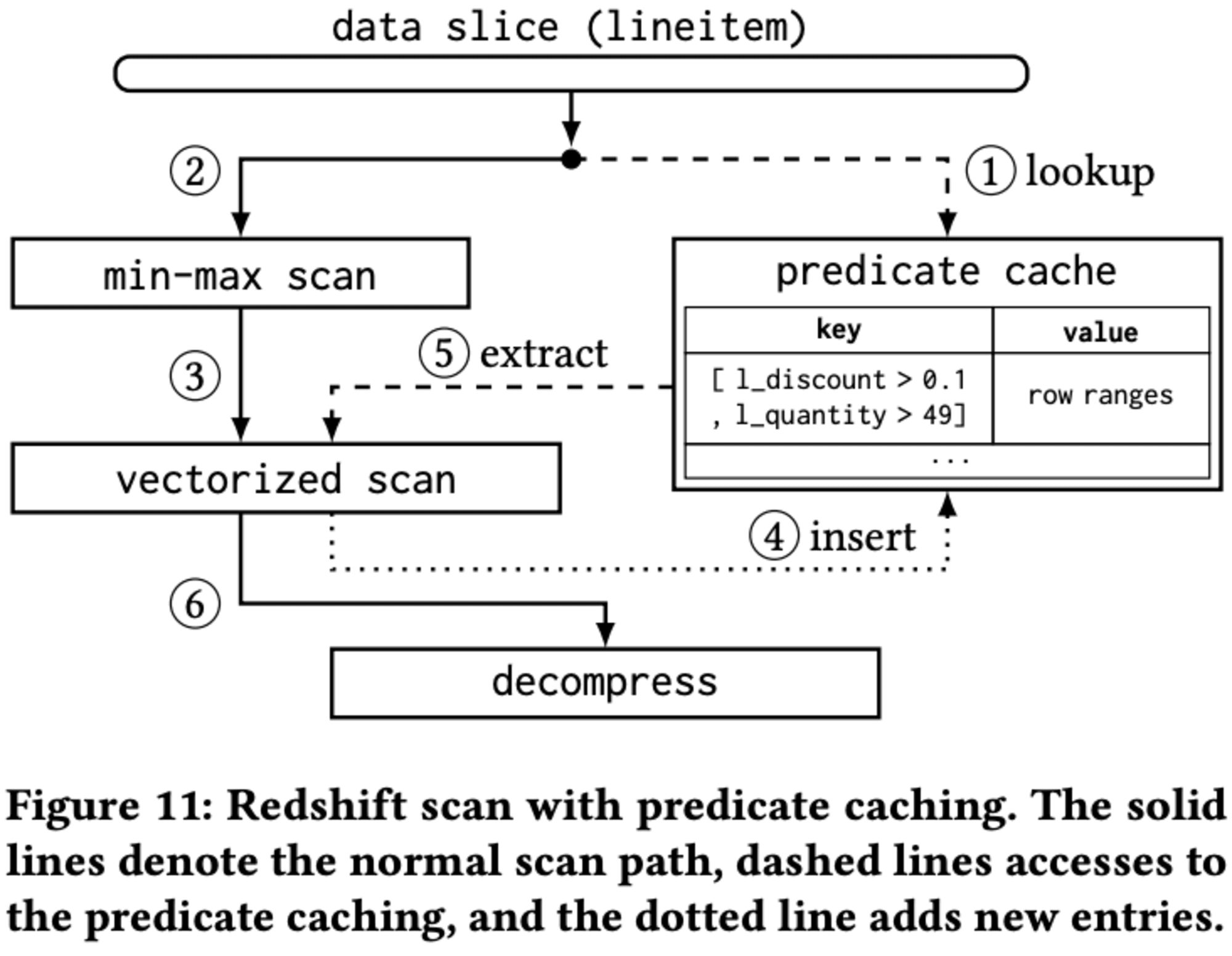
スキャン処理では、データスライスがさらに小さなコンピュートスライスに分割され、各スライスは1つのスレッドで処理されます。Redshiftは圧縮技術を使用し、2段階のスキャンプロセスを実装しています。まず、述語の最小-最大範囲に基づいてブロックを除外し、次に述語をベクトル化スキャンで評価します。
**4.2.3 Predicate Caching **
Predicate Cachingは、このスキャンプロセスに統合されています。キャッシュにヒットした場合、範囲制限スキャンをスキップし、キャッシュから直接行範囲を使用できます。これにより、スキャン処理が高速化され、クエリのパフォーマンスが向上します。この設計により、述語キャッシュは標準のスキャンプロセスに簡単に組み込むことができ、必要に応じてオン/オフを切り替えることができます。
4.3 Inserts, Deletes, and Updates
Predicate Cachingは、オンラインで構築が容易であり、顧客がデータの挿入、削除、更新しても有効性を保つという大きな利点があります。これにより、結果キャッシュやAutoMVなど他のキャッシング手法よりも汎用性が高くなっています。
4.3.1 Inserts
大量のデータ挿入を高度に最適化しています。主キーや外部キーの制約を強制せず、B-treeなどのインデックスも構築しないため、データの挿入が高速です。新しいタプルは挿入バッファの末尾に追加され、後のvacuumプロセスでマージされます。新しいタプルは末尾に追加され、より大きな行番号が割り当てられるため、キャッシュされたプレディケートの行範囲は有効なままです。キャッシュを無効化する必要はなく、代わりにデータスライスの最後にキャッシュされた行の番号を記憶し、新しいタプルは通常の範囲制限付きベクトル化スキャンで処理されます。
4.3.2 Deletes
Redshiftは、PostgreSQLと同様にタイムスタンプベースのマルチバージョン同時実行制御を実装しています。各行には作成と削除のタイムスタンプがあり、行の可視性を決定します。削除操作は削除タイムスタンプを設定し、後続のトランザクションに対して行を不可視にします。Predicate Cacheは削除を容易に処理し、削除された行がキャッシュされた行範囲に含まれていても、後続のスキャンで可視性チェック中に除外されます。
4.3.3 Updates
更新操作は、多くのOLAPシステムと同様に、Redshiftでは元の場所以外で実装されます。古いタプルは削除としてマークされ、新しいバージョンが挿入されます。これにより、更新は削除と挿入の組み合わせとして扱われ、述語キャッシュは引き続き有効です。
4.4 Extension as Join Index
Redshiftのクエリ最適化技術における述語キャッシュと準結合フィルターの組み合わせについて開設しています。
述語キャッシュは、以前はフィルター付きのスキャンにのみ使用されていましたが、Redshiftは準結合フィルターを実装し、ハッシュ結合をプローブ側のテーブルスキャンにプッシュできるようになりました。これにより、結合パートナーのない行を早期に除外できます。Redshiftは、ハッシュ結合のビルド側でブルームフィルターを構築し、それをプローブ側のテーブルスキャンに渡します。
述語キャッシュは、この**準結合フィルターの結果もキャッシュでき、スキャンベースのキャッシングとクエリベースの結果キャッシュの利点を組み合わせることができます。**ただし、これにはコストがかかります。キャッシュされたエントリのキーには、結合と構築側の関連部分を含める必要があり、より複雑になります。
この例では、完全なキーは次のようになります。
{ table: lineitem,
filters: [ l_discount = 0.1, l_quantity >= 40,
{ semi_join_filter: o_orderkey = l_orderkey,
build_side: [{
table: orders,
filters: [o_orderdate between '1995-01-01' and '1995-01-31']
}]
}]}
結合述語 o_orderkey = l_orderkey と構築側の表現を含めます。
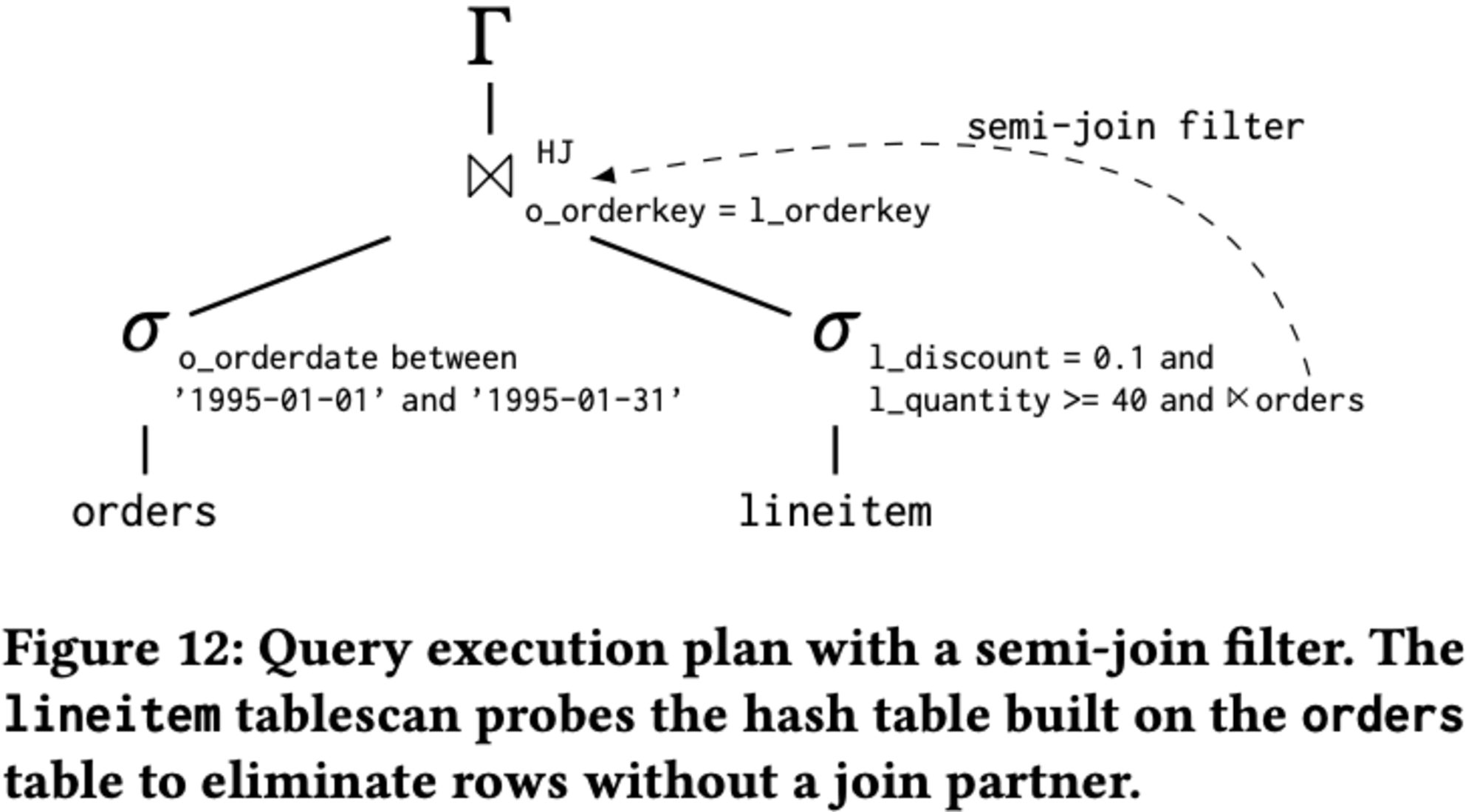
この組み合わせには利点と欠点があります。利点としては、キャッシュされたエントリがより選択的になり、スキャンされる行数が大幅に減少することです。一方、欠点としては、ヒット率の低下と、構築側のテーブルの変更によるキャッシュの無効化があります。
現代のクラウドデータウェアハウスでは、スタースキーマやスノーフレークスキーマが一般的であり、準結合フィルターを使用することで多くの行を早期に除外できるため、述語キャッシュに結合を含めることは多くのクエリにとって有益です。しかし、スキャンする行数の削減と、より複雑なキーや増加する無効化率のデメリットとのバランスを取る必要があります。
4.5 Supporting Open Data Formats
Amazon Redshiftは、独自の関係フォーマットをスキャンするためにPredicate Cachingを統合しました。しかし、現代のクラウドデータウェアハウスは、CSV、Apache Parquet、Apache ORCなどのオープンデータフォーマットもサポートしています。Redshift Spectrumアクセラレータは、これらのフォーマットでAmazon S3に保存された大量のデータをスキャンできます。
データレイクの台頭により、Apache IcebergやDelta Lakeなどの新しいオープンテーブルフォーマットをスキャンする機能が重要になっています。データレイクでは、他のシステムがデータセットを変更できるため、分析システムが効率的にデータをインデックス化することは困難です。しかし、述語キャッシュはデータの所有権を必要とせず、タプルの行番号の変更を検出するだけで済みます。
Predicate Cachingは、行を一意に識別でき、行番号の変更が頻繁でなく、テーブルの変更を検出してキャッシュエントリを無効化できるデータフォーマットに適用できます。また、テーブルの一部に細かくアクセスできるストレージフォーマットが望ましいです。Predicate Cachingは、データベースがデータの全ブロックのダウンロードや解凍を避けられる場合に最高のパフォーマンス向上を示します。
4.6 Putting It All Together
プレディケートキャッシングは、オンラインインデックスとしての設計目標を満たし、データの挿入、削除、更新時にも既存のエントリを無効化しません。ノードごとに状態を維持し、他のワーカーとの通信や同期を回避します。Redshiftはデータスキャン中に自動的にキャッシュエントリを構築し、追加作業を必要としません。また、行範囲のみを保存することでデータ依存性を回避します。この手法は汎用性が高く、
Apache IcebergやDelta Lakeなどの外部データ形式とも統合が容易です。ワークロード駆動型で、顧客が照会したデータのみをインデックス化し、大規模クラスタにも容易に対応できます。これにより、反復的なワークロードの利点を活かし、結果キャッシング、マテリアライズドビュー、ソートキーと共に、効率的なデータ処理を実現します。
5 EVALUATION
述語キャッシュの性能評価に関して、メモリ消費量、実世界のデータセットにおけるヒット率、構築オーバーヘッド、ベンチマークでの性能向上を調査し、述語ソーティングとの比較も行っています。述語ソーティングは、ワークロードの一般的な述語に基づいて行を整理する簡略化されたQd-treeアプローチの一種で、テーブルを物理的に再編成する特徴があります。
5.1 Experimental Setup
2023年9月、Amazon Redshiftの最新バージョンに述語キャッシュのプロトタイプを統合しました。範囲ベースとビットマップベースの両方のインデックスを実装し、主にビットマップインデックスを使用しています。実験は4ノードのRedshiftクラスターで行われ、TPC-H、TPC-DS、SSBベンチマークを使用しました。より現実的なシナリオを反映するため、歪んだTPC-Hデータジェネレーターも使用しています。実行時間はクエリの全体的な実行時間として報告されます。
5.2 Memory Consumption
TPC-Hベンチマークのクエリ6に対するデータ駆動型インデックスとワークロード駆動型キャッシュのメモリ消費量を比較しています。標準的なB+ツリーインデックスは大量のメモリを必要とする一方、ZoneMapはより効率的です。
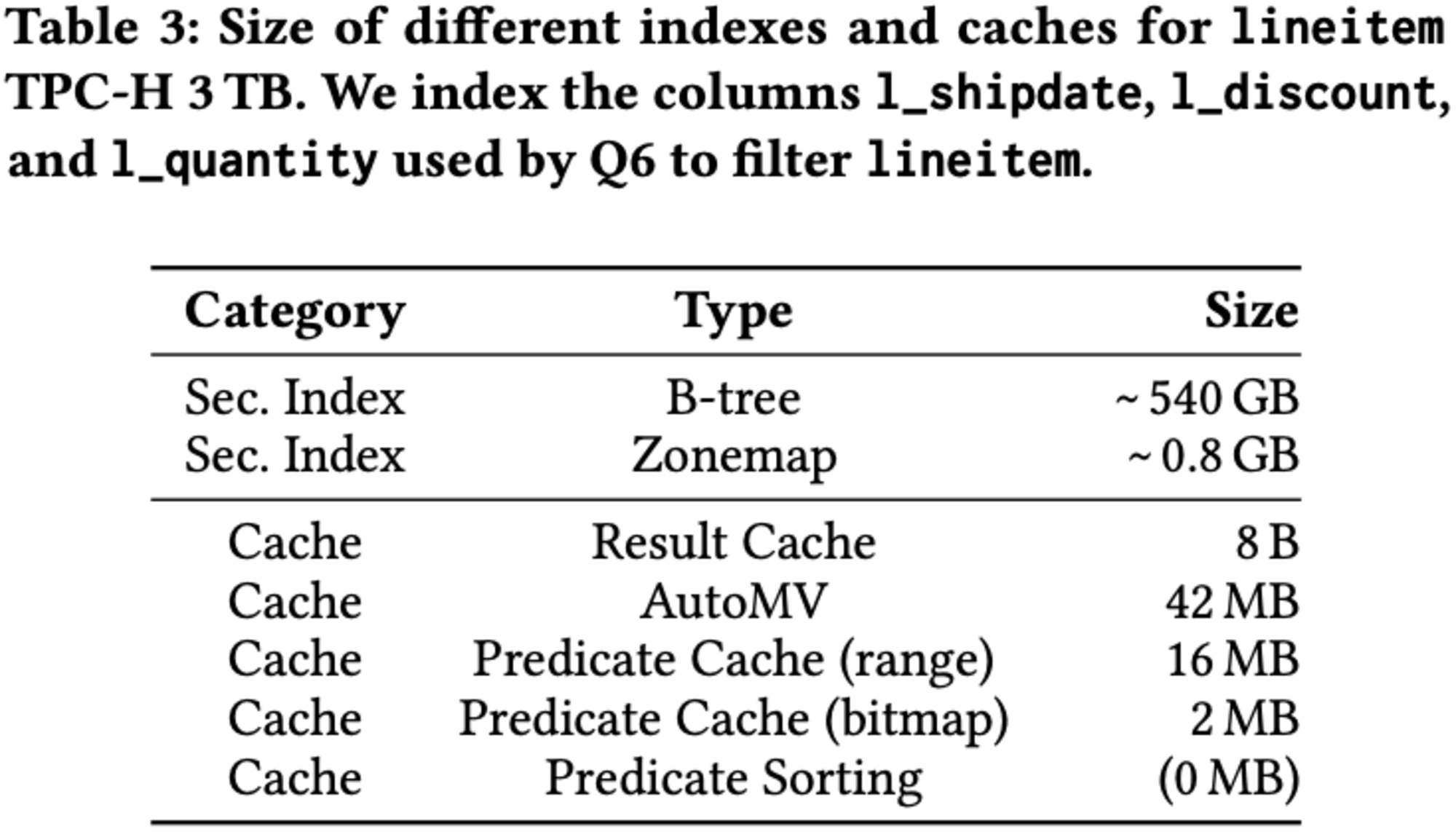
キャッシュはインデックスよりもさらに小さく、結果キャッシングが最も省スペースです。自動マテリアライズドビューもこのクエリに適しています。述語キャッシュは実装によって異なるサイズになりますが、テーブルサイズに比例したメモリを割り当てます。ソーティングベースのアプローチは追加メモリを必要としませんが、テーブルの再編成が必要です。結果キャッシュとAutoMVのサイズはクエリに依存しますが、述語キャッシュはテーブルサイズに比例するため、管理が容易です。
5.3 Hit Rate
述語キャッシュのヒット率を 2 つの内部ワークロード (ワークロード A と B) で評価します。どちらのワークロードも顧客クラスターをシミュレートし、Redshift で観察されるクエリ ストリームに基づいています。
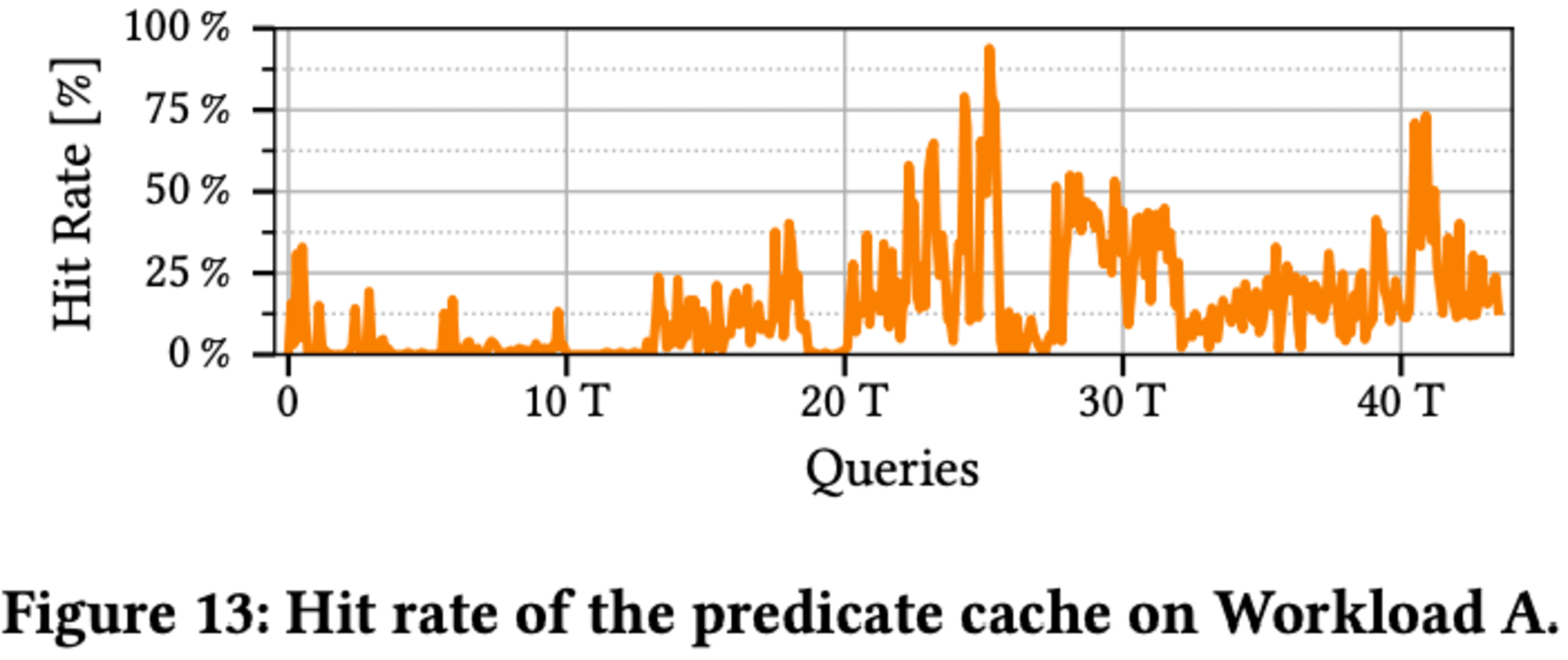
Workload Aにおける述語キャッシュのヒット率の時間変化について、数時間で44,000クエリを実行し、最初は空のキャッシュで低ヒット率ですが、15,000クエリ処理後にヒット率が上昇し、より多くのクエリがキャッシュを利用できるようになります。
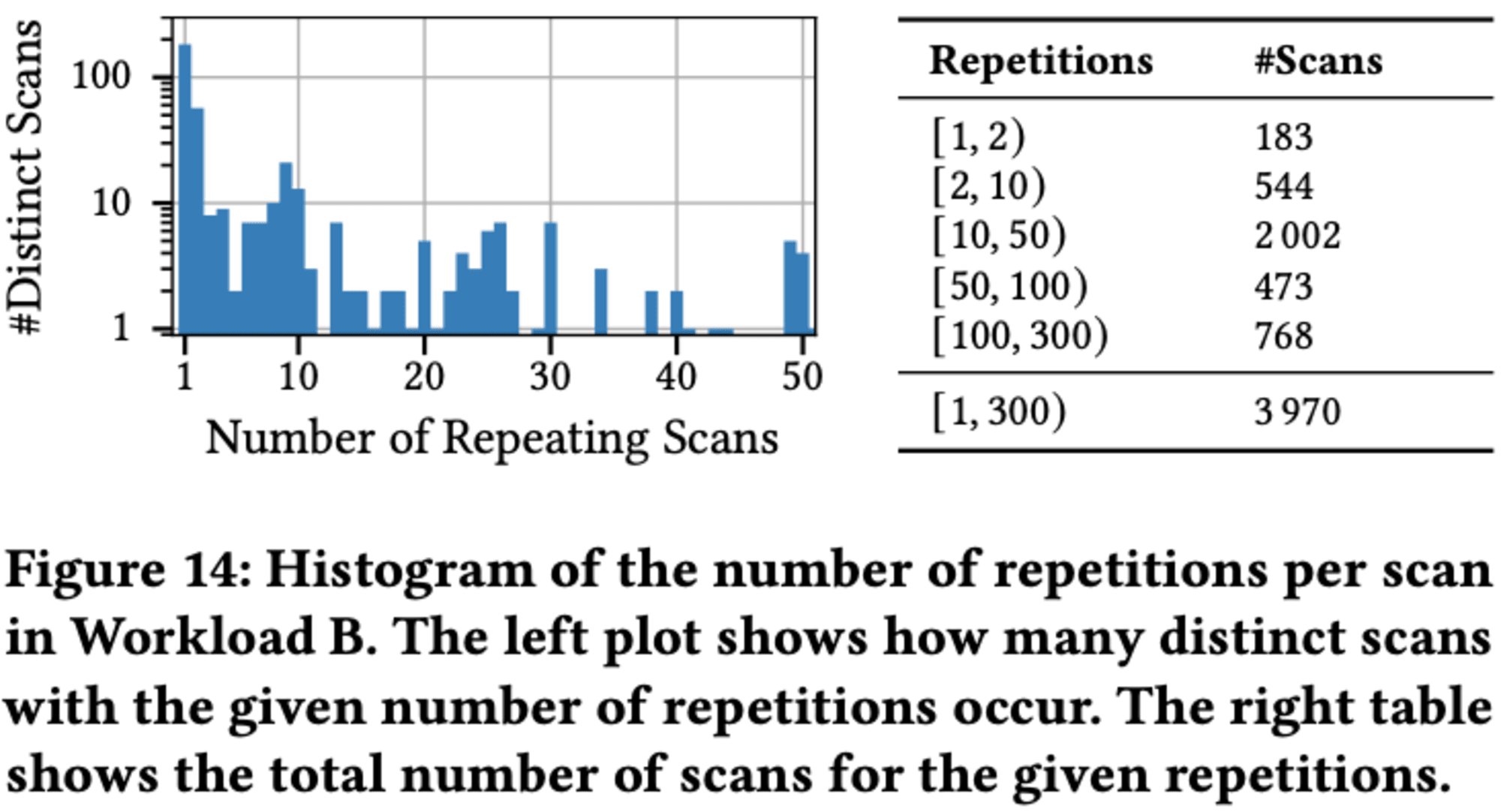
Workload Bにおけるスキャンの繰り返し頻度を分析した結果、高い反復性が明らかになりました。約4,000回実行されたスキャンのうち、ユニークなものは401回のみでした。218種類のスキャンが複数回実行され、183種類が1回のみ実行されました。特に注目すべきは、10回以上繰り返されたスキャンが全体の80%以上を占め、3,243回に達したことです。この結果は、ワークロードの効率化の可能性を示唆しています。
5.4 Build Overhead
Predicate Cacheの重要な特徴は、構築に伴うオーバーヘッドが最小限であることです。このキャッシュは、クエリ処理の副産物として構築できる軽量なデータ構造として特別に設計されています。実験では、TPC-HとTPC-DSを空のキャッシュで実行し、フィルタプレディケートを持つすべてのスキャンに新しいエントリをキャッシュに挿入させました。
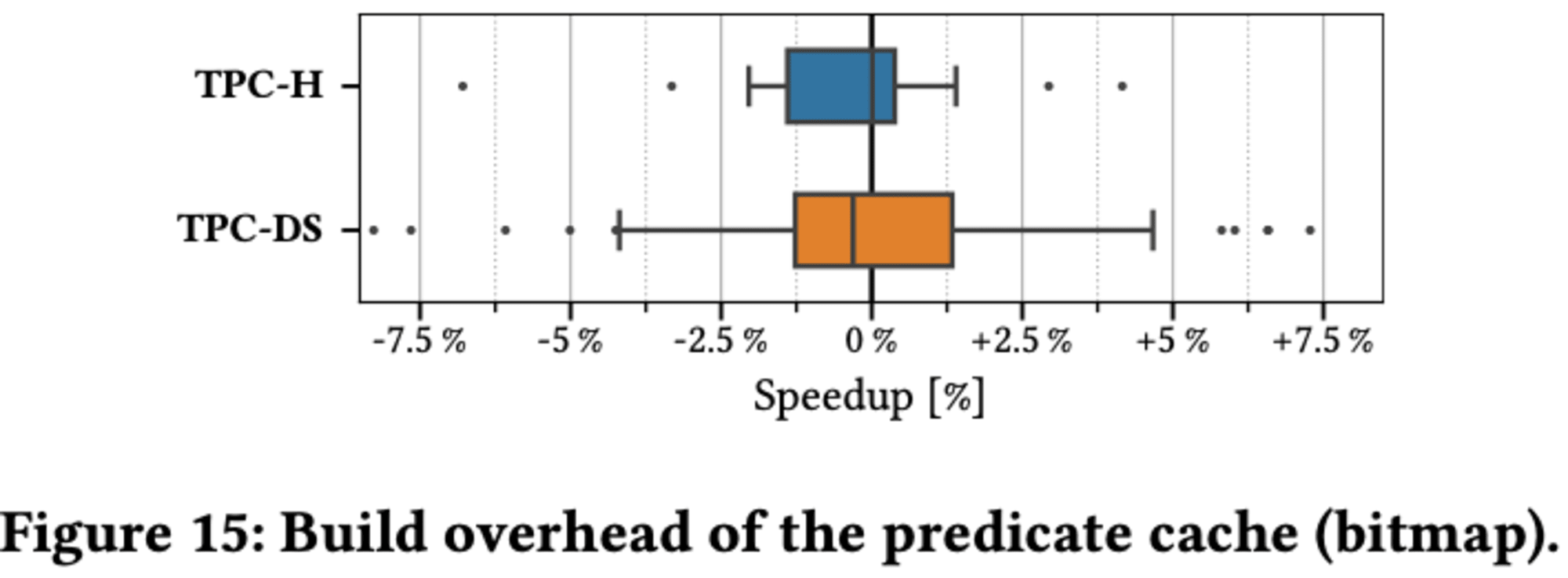
ほとんどのクエリでは、パフォーマンスに大きな差は見られず、速度の向上や低下は1%以内でした。一部のクエリでは最大8%の変動が見られましたが、これらは孤立したケースであり、平均実行時間の低下は両ベンチマークとも0.5%未満でした。結果として、Predicate Cacheへの新しいエントリの追加によるオーバーヘッドはほとんど測定不可能であり、実際のクエリ実行が実行時間の大部分を占めていることが分かりました.
5.5 Query Performance
Predicate Cacheの効果について、研究者たちは、TPC-Hベンチマークの歪んだバージョンをRedshiftで実行し、Predicate Cacheの有無による性能の違いを調査しました。全体として、Predicate Cacheを使用することで10%の性能向上が観察されました。特筆すべきは、スキャンされる行数が約4分の1に、アクセスされるブロック数が30%減少したことです。
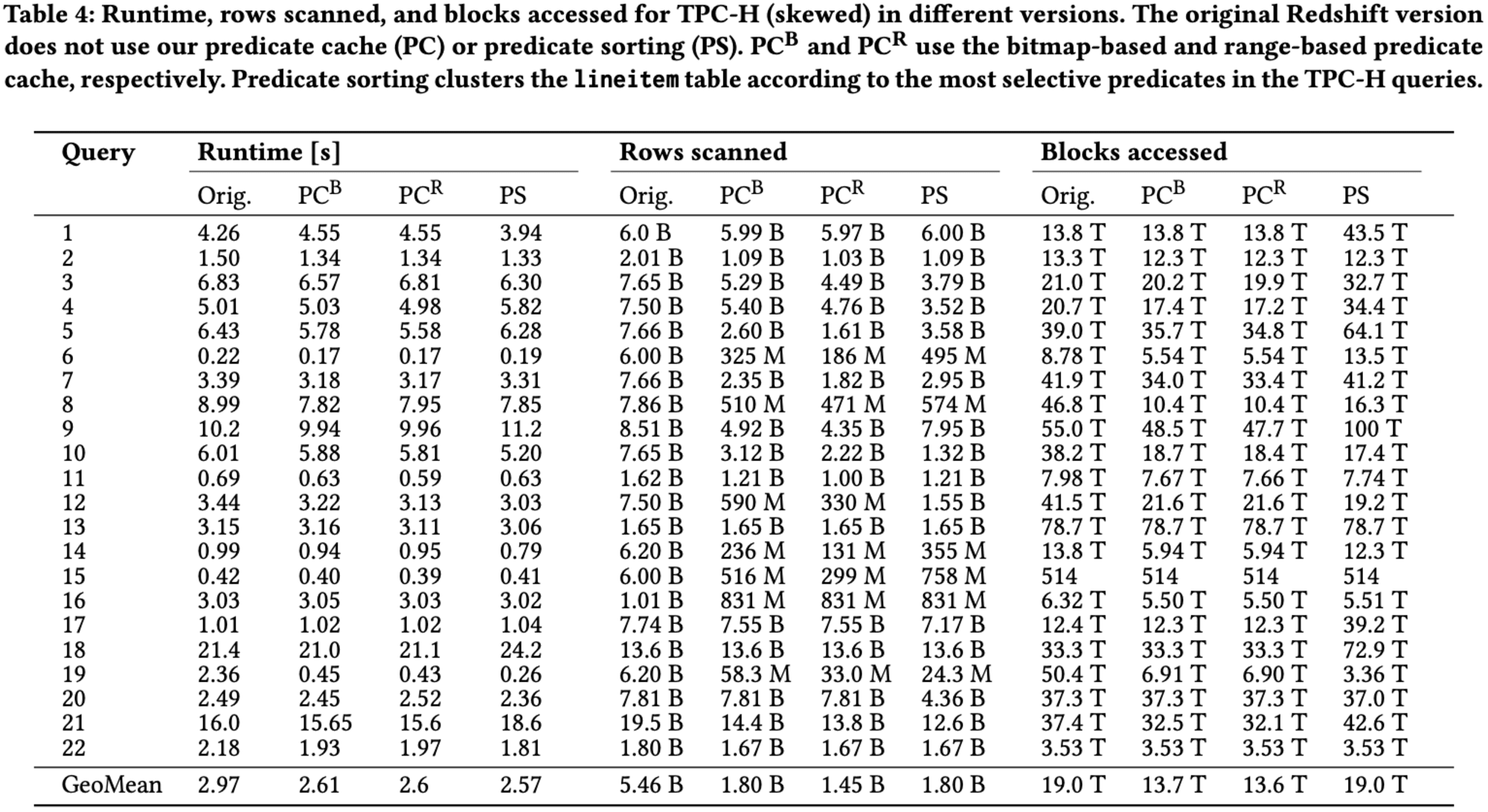
性能向上の度合いは、主にアクセスされるブロック数と相関関係にあります。例えば、クエリ19では、述語キャッシュによってアクセスされるブロック数が7.3倍減少し、実行時間が5.2倍速くなりました。一方、スキャンされる行数の減少は、全体的な性能にそれほど大きな影響を与えませんでした。
5.5.1 Impact of Semi-Join Filters
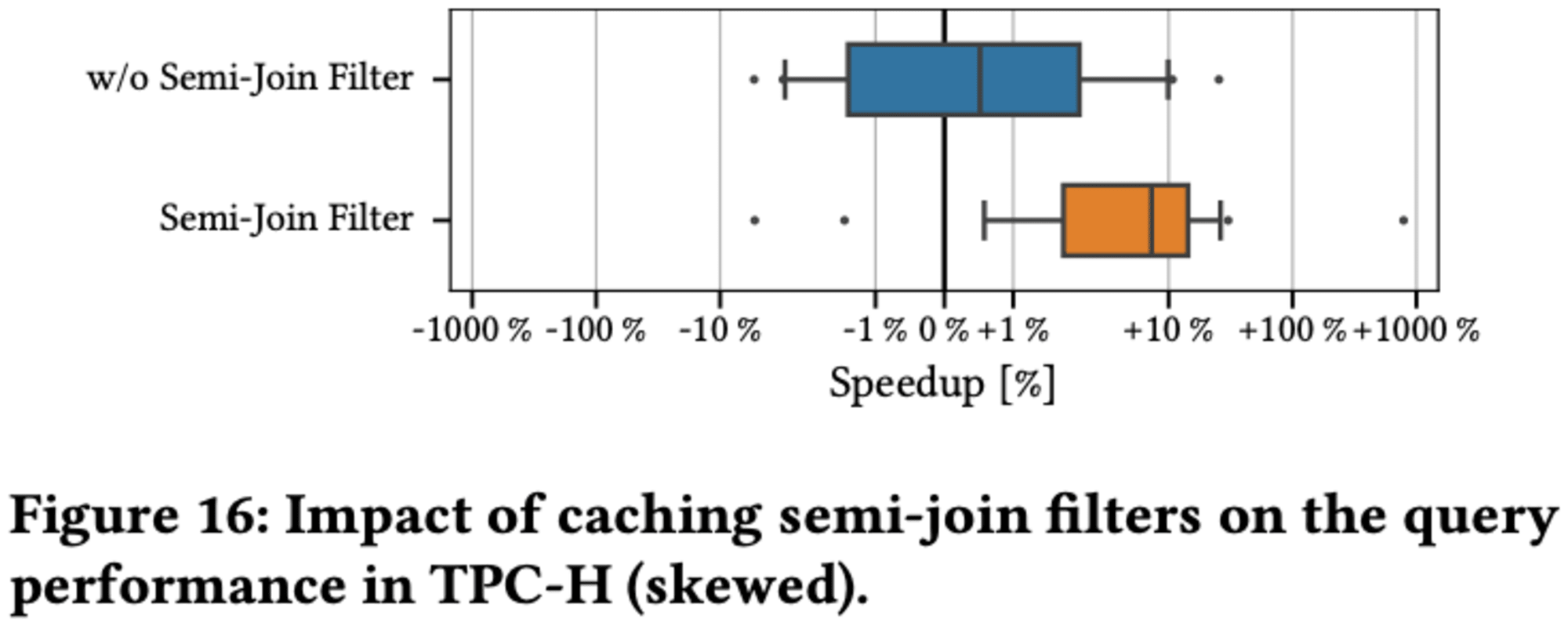
研究者たちは、セミジョインフィルターを述語キャッシュに統合することで、さらなる性能向上が可能であることを発見しました。これは特に、ファクトテーブルがディメンションテーブルとフィルタリングおよび結合される、スノーフレークのようなスキーマを持つクラウドデータウェアハウスで効果的です。
5.5.2 End-to-End Performance
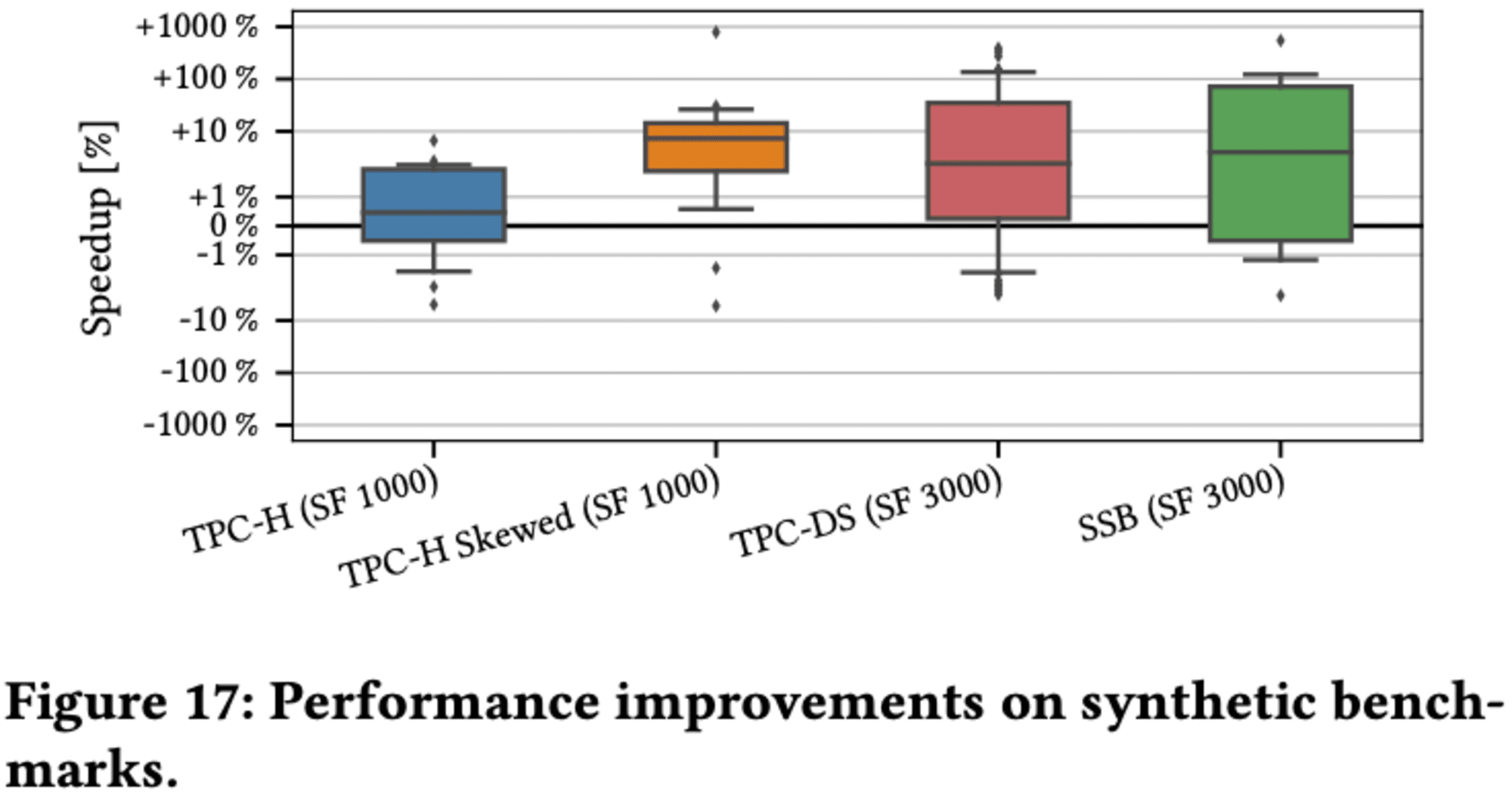
また、TPC-DSやSSBなど他のベンチマークでも同様の結果が得られました。ただし、これらのベンチマークではデータがほぼ均等に分布しているため、選択的な述語が全ブロックを除外することは難しくなっています。研究者たちは、述語キャッシュがより不均一な分布を持つデータセットでより良い性能を発揮すると結論付けています。
5.6 Predicate Caching vs. Sorting
TPC-Hベンチマークの偏りのあるバージョンでは、これらの技術が同様のパフォーマンス向上をもたらすことが示されています。述語に基づいてテーブルを物理的に分割すると、スキャンされる行数が3分の2に減少しますが、クエリの選択性が高くない限り、アクセスされるブロック数は改善されません。これは、ソートされたテーブルレイアウトがデータ圧縮を最適化できず、テーブル内のブロック数が増加するためと考えられます。
両技術は同様の効果を達成しますが、ソーティング技術の方がわずかに大きな実行時間の改善をもたらします。より選択的なクエリや、わずかに変化するワークロードに対しては、ソーティングがより効果的であると予想されます。
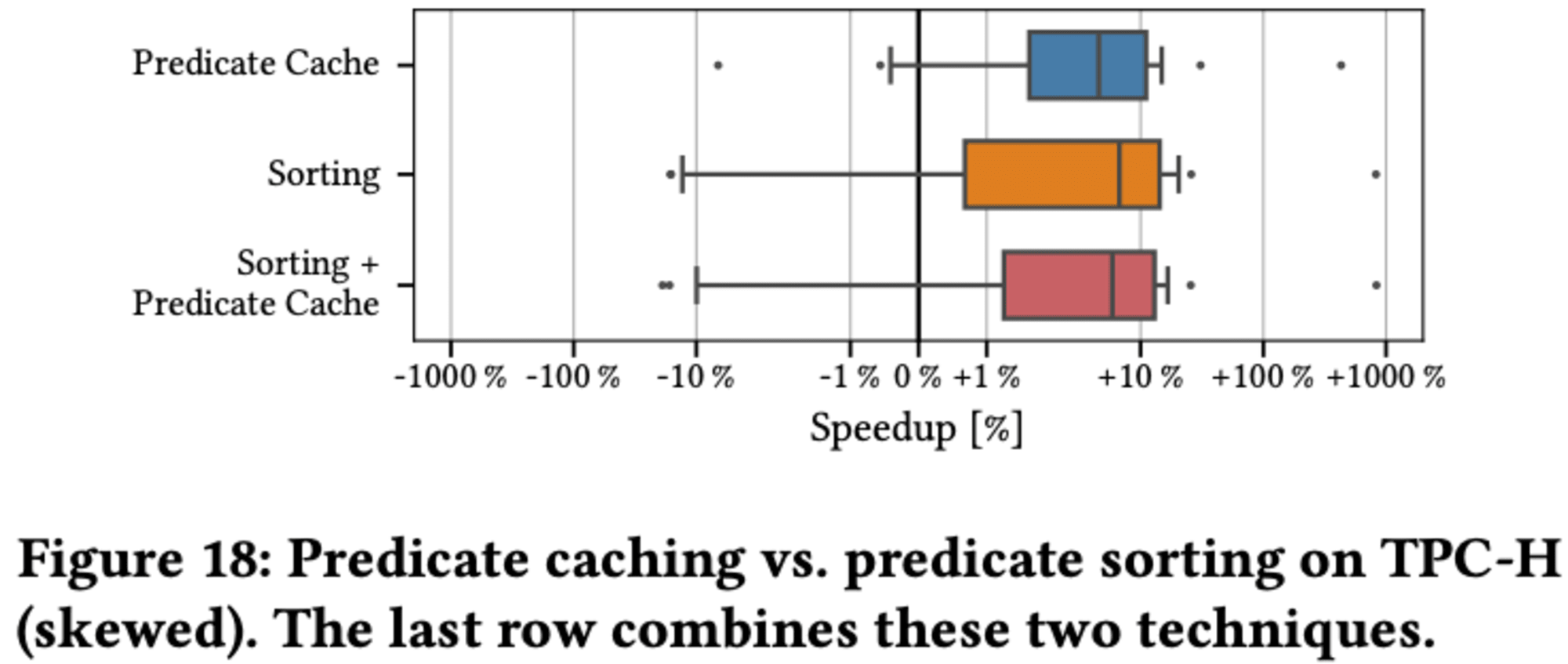
しかし、これら2つのアプローチを組み合わせても、TPC-Hにおいては追加の性能向上は観察されませんでした。実世界のシナリオでは、Predicate Cachingと多次元ソーティングを組み合わせることで、両技術の利点を活用できる可能性があります。ワークロードに基づいてテーブルをソートすることで、クラウドデータウェアハウスのデータ取得と解凍のオーバーヘッドを削減できます。一方、Predicate Cachingは、ソートキーでカバーされていない最新の述語をインデックス化するのに役立ちます。
最終的に、述語キャッシュによって収集された統計に基づいて、データベースはテーブルの再編成とデータレイアウトの変更を決定できます。これにより、変化するワークロードに対して柔軟に対応することが可能になります。
6 RELATED WORK
データウェアハウスにおけるスキャンパフォーマンスを加速させる技術とインデックス構造は、主に3つのカテゴリーに分類されます。データスキッピングインデックス、データ再編成技術、そしてセマンティッククエリです。
Data skipping
データスキッピングは、Small Materialized Aggregates (SMAs)やZoneMapsなどの技術を用いて、クエリの述語に基づいてブロックを除外します。これらは各列の最小値と最大値をブロックごとに保存し、スキャン操作の効率を向上させます。MonetDB、Snowflake、Redshift、HyPerなどの現代的なカラムナーデータベースの多くがこの技術を採用しています。
ビットマップインデックスも一般的に使用され、値を行やブロックにマッピングします。Column Imprints、Column Sketches、Bindexなどは、ビットベクトルを使用して個々の値をインデックス化します。一方、Cuckoo Indexはメモリフットプリントを最小限に抑えるため、ブロックのみをインデックス化します。
最近では、ワークロード駆動型のアプローチが注目されています。Snowflakeの検索最適化サービスは、マイクロパーティション内の列の値を追跡します。また、Smooth Predicate Acceleration (SPA)フレームワークは、スキャンを加速するためにオンザフライでセカンダリインデックスを構築します。
Data reorganization
データ再編成技術では、データのソートが重要です。SnowflakeやRedshiftなどのクラウドデータウェアハウスは、自動的にデータをクラスタリングできます。しかし、データ駆動型のソートには次元数の制限があるため、Qd-treeやその後継技術などのワークロード駆動型アプローチが提案されています。
Semantic caching
セマンティックキャッシングは、クエリの述語に基づいてキャッシュされたデータを再編成します。Crystalなどの技術は、特に集計や結合が関与する場合に大きな性能向上をもたらす可能性があります。
これらの技術は互いに補完し合い、データウェアハウスのパフォーマンスを総合的に向上させます。例えば、述語キャッシュは、物理的なデータレイアウトが変更されない限り、既存のデータに対して有効であり、他の技術と組み合わせて使用できます。このように、様々なアプローチを組み合わせることで、データウェアハウスのスキャンパフォーマンスを最適化することが可能となります。
CONCLUSION
プレディケートキャッシングは、大規模データウェアハウス向けの軽量なキャッシング技術です。クエリ処理中に動的に構築され、パフォーマンスの低下を回避します。基礎データの更新がキャッシュを無効化せず、新しいデータを再構築なしで段階的に統合できる点が特徴です。シンプルな設計により、Apache IcebergやDelta Lakeなどのオープンデータ形式との容易な統合が可能です。この技術は、高コストの具体化ビューと低ヒット率の軽量技術の間のギャップを埋めます。顧客ワークロードで高いヒット率を達成し、テーブルが頻繁に更新される場合でも効果的です。さらに、セミジョインフィルターを含めることで、最大10倍のパフォーマンス向上が可能となります.
最後に
Predicate Cachingは、クエリの述語条件と該当する行の範囲をキャッシュする軽量な技術です。著者らは、クラウドデータウェアハウスのワークロードが非常に反復的であることに着目し、既存のキャッシュ技術(結果キャッシュ、マテリアライズドビュー、ソーティング)の課題を指摘しています。
これらの技術には、構築コストが高い、更新に弱いなどの問題があります。Predicate Cachingは、これらの課題を解決するために設計されました。オンラインで構築可能で、データ更新に強く、メモリ使用量も少ないのが特徴です。さらに、セミジョインフィルタも考慮することで、より効果的にデータスキップが可能になります。
2023年には、Qd-treeの着想に基づき、自動化された多次元データレイアウトやPredicate CachingをRedshiftに実装して検証したのは驚きでした。論文の中では、多次元レイアウトが前提でPredicate Cachingが論じられていますが、多次元レイアウトもまだ一般提供開始ではない機能です。このre:Invent 2024の先取りのような論文です。
Predicate Cachingは、Amazon Redshiftはもちろん、この技術はApache IcebergやDelta Lakeなどのオープンデータフォーマットにも適用可能であり、クラウドデータウェアハウスの性能を向上させ、反復的なワークロードを効率的に処理するための新しいアプローチを提供できるということです。今年のre:Invent 2024が楽しみです。
筆者補足: Qd-tree
なんの脈絡もなく出てきた「Qd-tree」について解説します。Qd-treeとは"Query-data routing tree"の略称です。これは大規模データ分析のためのデータレイアウトを最適化する新しいフレームワークです。Qd-treeは、与えられたワークロードに対してI/O効率の良いデータレイアウトを生成することを目的としています。具体的には、クエリパターンに基づいてデータをブロックに割り当てることで、クエリが必要とするブロック数を最小限に抑え、データスキッピングを可能にします。このアプローチにより、従来のデータ分割手法と比較して、クエリのパフォーマンスを大幅に向上させることができます。Qd-treeの構築には、貪欲法(greedy algorithm)や深層強化学習などのアルゴリズムが使用され、効率的なデータアクセスパターンを学習します。
論文を読んでると、数珠つなぎに論文を読んで時間が溶けてしまう、、、ありがちですね。









